
从图形渲染的专属工具到人工智能的算力核心,GPU的产业价值随技术迭代持续攀升。在中国AI产业高速发展的浪潮中,国产GPU迎来了政策扶持与市场需求的双重红利。2025年底以来,摩尔线程、沐曦股份相继登陆科创板,壁仞科技、天数智芯打响2026年IPO开门红,一轮密集的上市潮为行业注入强劲动能。站在这一关键节点,展望2026年国产GPU领域的发展态势,不难发现,在市场格局重构、资本加速入局与技术创新突破的多重驱动下,国产GPU正迈入高质量发展的关键阶段。
云端深耕与边缘爆发,市场面临双重机遇
2026年,人工智能产业“云端深耕+边缘爆发”的双重格局将逐渐成型,为国产GPU企业开辟广阔的市场空间。在云端领域,随着大模型参数从千亿迈向万亿级,训练算力需求每3-6个月翻番,单次前沿大模型训练算力需求已达350-500 PF-days,超大规模数据中心的算力升级需求迫切。同时,企业级推理集群成为算力消耗主力,德勤预测2026年推理占AI计算量的66%,同比增长120%-150%。政务、金融、互联网等领域的国产化替代需求持续升温,为海光信息、沐曦股份等聚焦高端算力的企业提供了核心增长机遇。
在边缘领域,工业互联网、自动驾驶、数字孪生等场景的落地应用进入爆发期,推动边缘算力需求同比增长150%以上。2026年全球将部署100万个边缘AI节点,单节点算力需求达3 TFLOPS,工厂级AI服务器部署量预计突破5万台。这种轻量化、低延迟的算力需求,为景嘉微、摩尔线程等具备多场景适配能力的企业创造了差异化竞争机会。摩尔线程的MTT S5000等产品可覆盖边缘AI计算、图形渲染等多元场景,边缘场景的市场机会不断涌现。此外,端侧推理市场的快速崛起也不容忽视,AI手机、PC的普及推动端侧算力同比增长300%,为国产GPU企业拓展消费级市场提供了新的增长点。
上市潮持续涌动,A+H布局成新趋势
2025年底开启的GPU企业上市潮,在2026年持续发酵,成为推动行业发展的重要引擎。继摩尔线程、沐曦股份登陆科创板,壁仞科技、天数智芯挂牌港交所后,2026年行业“四小龙”之一的燧原科技已完成IPO辅导,即将申报科创板;百度旗下昆仑芯也正式向港交所递交上市申请,瀚博半导体等企业亦在冲刺IPO的队列中,国产GPU领域的资本集结进入收尾阶段。资本市场的加持,不仅为企业带来研发投入的资金支撑,更有助于其完善产业链布局、提升品牌影响力。以壁仞科技为例,其1月2日在港交所上市首日涨幅达75.82%,总市值一度超过1000亿港元,充足的资本储备为其技术迭代和市场拓展奠定了坚实基础。
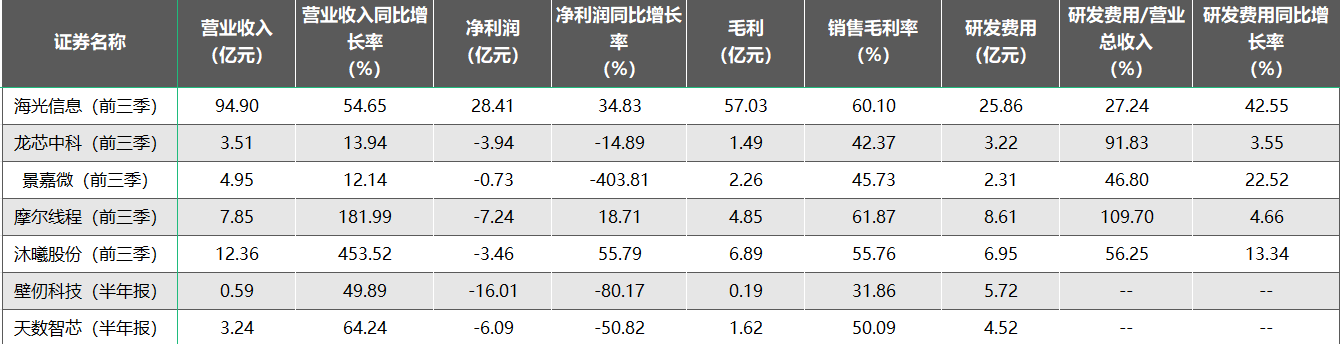
值得注意的是,壁仞科技在启动IPO时已准备“A+H”上市方案,天数智芯招股书中未排除未来申请A股上市的可能性。未来,一旦A股政策窗口打开、估值体系优化,部分已在港股上市的企业有望开启A+H布局。在港股完成资本积累后,回归A股将进一步拓宽融资渠道,提升在国内市场的话语权。
不过,资本的狂欢背后,上市企业也将面临新的挑战。一方面是市场对企业业绩兑现的预期不断提升,业绩表现将直接影响企业估值;另一方面,上市后企业需接受更严格的监管监督,研发投入的持续性、盈利模式的稳定性等问题将被持续关注,行业将迎来“资本筛选”的新阶段,缺乏核心技术和商业化能力的企业将逐步被淘汰。
架构迭代与生态突破双轮驱动
2026年,国产GPU的技术竞争将聚焦于AI原生架构、异构集成、能效比提升及CUDA生态兼容四大核心方向,技术创新成为企业突围的关键。在架构设计上,AI原生架构成为主流选择,沐曦股份的XCore架构专为AI训推一体打造,千卡集群线性扩展效率达88%-90%,单集群支持1024卡以上;摩尔线程的MUSA统一架构则追求全场景覆盖,旗舰产品MTT Z7000 FP32算力达32 TFLOPS,夸娥集群扩展效率95%,支持十万卡级智算集群。
异构集成与能效比提升成为破解算力瓶颈的重要路径。受限于先进制程产能,国产GPU企业纷纷通过Chiplet技术、3D芯片堆叠等异构集成方案提升性能,AMD Instinct MI455X GPU采用12个2纳米和3纳米制程的计算及I/O Chiplet,实现了3200亿晶体管规模与432 GB HBM4显存的配置,为国产企业提供了技术借鉴。在能效比方面,英伟达Rubin GPU通过NVFP4 Tensor Core技术,在晶体管数量仅增长1.6倍的情况下,推理性能提升5倍,生成每个token的成本低至十分之一,这种“性能-成本”平衡的技术方向,将成为国产GPU的重要研发目标。
生态建设仍是国产GPU突破垄断的核心壁垒。当前,CUDA生态兼容成为短期快速起量的关键,沐曦股份的MXMACA软件栈适配6000+主流AI应用,政务、金融客户迁移成本几乎为0;摩尔线程则通过MUSIFY转译工具支持CUDA代码自动转换,Torch-MUSA算子超1050个,适配主流框架,MUSA开发者生态注册用户超15万人。2026年,生态竞争将从“兼容适配”向“自主创新”升级,国产GPU企业需在指令集、软件栈、开发者社区等方面持续投入,构建不依赖于国外生态的自主体系。同时,与国产OS、CPU的协同优化将成为重要方向,摩尔线程MUSA架构对国产软硬件的支持,海光信息与国产整机厂商的深度合作,都将推动国产算力生态的整体成熟。
结语
2026年,国产GPU领域将迎来机遇与挑战并存的发展格局。市场端,云端与边缘的双重需求为企业提供了广阔空间;资本端,上市潮的持续涌动加速行业洗牌,推动资源向头部企业集中;企业端,业绩分化倒逼企业明确差异化发展路径;技术端,架构迭代与生态突破成为核心竞争力。展望未来,随着技术的持续创新、生态的不断完善以及产业链协同能力的提升,2026年有望成为国产GPU从“跟跑”向“并跑”跨越的关键一年,为中国人工智能产业的自主发展奠定坚实的算力基础。








